Yếu tố 3: Giá cả – Nên tính theo giờ hay số tác vụ?

Menu
Điều cần thiết thứ ba để ghi nhãn dữ liệu cho máy học là giá cả. Mô hình mà dịch vụ ghi nhãn dữ liệu sử dụng để tính giá là một nhân tố ảnh hưởng tới tổng chi phi dự án và chất lượng dữ liệu.
Dịch vụ ghi nhãn dữ liệu tính phí như thế nào?
Thông thường, các dịch vụ ghi nhãn dữ liệu tính phí theo tác vụ hoặc theo giờ và dựa trên mô hình được áp dụng để đưa ra mức giá. Nếu trả tiền trên mỗi tác vụ hoàn thành, điều này có thể khuyến khích việc hoàn thành càng nhiều tác vụ càng tốt, dẫn đến dữ liệu kém chất lượng sẽ trì hoãn việc triển khai và lãng phí thời gian.
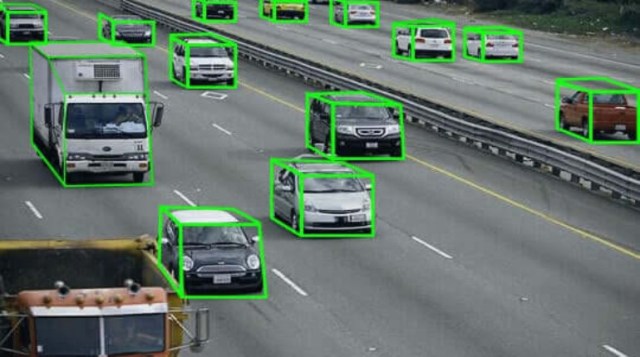
Ngược lại, khi được trả tiền dựa trên thời gian làm việc sẽ khuyến khích nhân công thực hiện đúng nhiệm vụ, đặc biệt là các nhiệm vụ phức tạp hơn và đòi hỏi sự chủ quan ở cấp độ cao hơn. Sự khác biệt này có ý nghĩa quan trọng đối với chất lượng dữ liệu và trong phần tiếp theo, chúng tôi sẽ đưa ra bằng chứng từ một nghiên cứu gần đây nêu bật một số khác biệt chính giữa hai mô hình.
Nghiên cứu về chất lượng và chi phí ghi nhãn dữ liệu.
Tại Hivemind đã thực hiện một nghiên cứu về chất lượng và chi phí ghi nhãn dữ liệu. Họ tranh thủ một lực lượng lao động được quản lý, được trả lương theo giờ và một nền tảng cung cấp dịch vụ đám đông hàng đầu, nhân viên ẩn danh, được trả để hoàn thành một loạt các nhiệm vụ giống hệt nhau. Mục tiêu của Hivemind cho nghiên cứu là tìm hiểu các nhân tố này một cách chi tiết hơn – để xem nhóm nào cung cấp dữ liệu chất lượng cao nhất và với chi phí tương đối.
Cùng một nhiệm vụ, hai lực lượng ghi nhãn dữ liệu khác nhau.
Tác vụ thực thi trên thể loại văn bản và độ khó dao động từ cơ bản đến phức tạp. Hivemind đã gửi các nhiệm vụ cho crowdsourcing workers với hai mức chi phí khác nhau, một nhóm nhận được nhiều hơn, để xác định chi phí bỏ ra có tác động như thế nào đến chất lượng dữ liệu.
Nhiệm vụ A: Văn bản có độ khó cơ bản
Crowdsourcing workers có độ sai sót khoảng 7% trên tổng số tác vụ. Khi họ được trả gấp đôi, tỷ lệ lỗi giảm xuống dưới 5%, đây là một sự cải thiện không đáng kể. Các nhân viên được quản lý bởi chúng tôi chỉ có tỷ lệ lỗi 0.4% trên tổng số tác vụ, một sự khác biệt quan trọng đối với chất lượng dữ liệu. Nhìn chung, trong nhiệm vụ này, crowdsourcing workers có tỷ lệ lỗi cao hơn gấp 10 lần lực lượng lao động được quản lý.
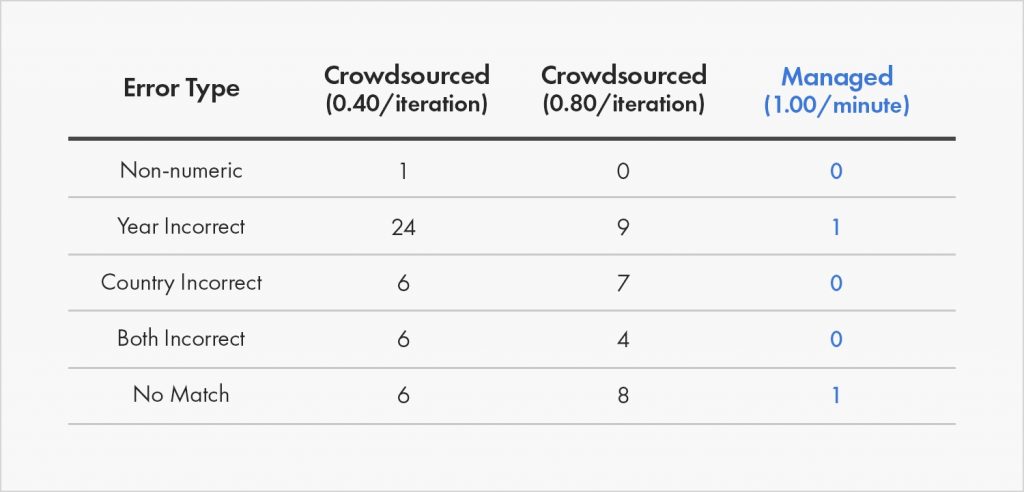
Nhiệm vụ B: Phân tích cảm tính
Nhân viên nhận thực hiện đánh giá bằng cảm tính dựa trên thang đo từ một đến năm trên một website chuyên review. Nhân viên được quản lý có độ chính xác phù hợp, đánh giá chính xác trong khoảng 50% trường hợp. Crowdsourced worker có một vấn đề, đặc biệt là với các đánh giá kém. Độ chính xác gần như 20%, về cơ bản giống như đoán, cho các đánh giá 1 và 2 sao. Đối với các đánh giá 4 và 5 sao, có rất ít sự khác biệt giữa hai lực lượng lao động.
Nhiệm vụ C: Trích xuất thông tin từ văn bản phi cấu trúc
Nhân viên sử dụng tiêu đề và mô tả về sản phẩm để phân loại theo 11 tiêu chí, bao gồm cả các sản phẩm không nằm trong nhóm và không được cung cấp đầy đủ thông tin. Độ chính xác của crowdsourced workers là 50% đến 60%. Nhân công được quản lý đạt độ chính xác 75% đến 85%, cao hơn 25% so với crowdsourced.
Trên đây là các thông tin giúp bạn quyết định vấn đề chi phí giá cả cho một dự án. Hy vọng điều này có thể giúp bạn tiến hành dự án với chi phí nhân sự được cân nhắc một cách hợp lý theo những nhu cầu của công ty mình.
Ngoài ra, bạn có thể tìm đọc thêm về các yếu tố khác như:
Yếu tố 1: Chất lượng và độ chính xác của dữ liệu
Yếu tố 2: Up Scale khi khối lượng xử lý dữ liệu tăng
Yếu tố 4: Bảo mật dữ liệu